Serverless testing strategy
Developers who start with AWS Lambda and other serverless technologies (SQS, EventBridge, Step Functions, …) often wonder how they should test their applications. And it’s not just about testing but more globally about Developer eXperience (DX):
- One of the main criteria is often the speed, and how they can shorten the feedback loop between the code and the result of the code. Developers (and their managers) don’t want to waste time, waiting for compilation, deployment or tests execution.
- Another essential criteria is the accuracy of the feedback: everyone wants reliable information (no flaky test) and be confident that if the tests are ok, the application will be ok.
- And lastly, precision of the feedback is also key to determine the origin of an error or a failed test. The more precise, the faster it is to correct.
An additional criteria is often added on top of these by managers: the cost. I already mentioned the time wasted to wait, which has a cost, but when talking about the cloud, there’s also the price for the resources we use in the cloud. We can also include the cost of writing automated tests.
This blog post describes different automated testing options for serverless applications and their appreciation on each of these 4 axis. I’ll give my recommended “strategy” in the conclusion.
Disclaimer: this blog post represents my personal thoughts and is not endorsed by AWS.
Disclaimer 2: this blog post is not intended to be exhaustive, and there are certainly uses cases that do not fit in the proposed solutions. One size doesn’t fit all! But in that case, I’m happy to know your use case.
Rather ‘test pyramid’ or ‘testing honeycomb’?

The aim of this section is not to provide an umpteenth description and battle between each “shape”, but to introduce some vocabulary that will be useful in the next sections. If you are not confident with the two notions, have a look at these articles: Test Pyramid (by Martin Fowler), and Testing of Microservices (by the Spotify Engineering Team). In summary, the test pyramid suggests that developers focus on “unit tests“, while the honeycomb favours the ”integration tests“. And just like operating systems (Windows vs Linux, Android vs iOS), each one has its defenders and detractors.
I personally like unit tests as they are supper fast, super precise and quite cheap and thus I would have a preference for the pyramid but:
- Not everyone agree on the same definition of unit tests, and where is the limit between unit and integration. I really like this article from Martin Fowler and the introduction of ‘sociable tests’ and ‘solitary tests’:

Do we consider sociable tests as unit tests or integration tests? Some people will tell unit tests should validate code in isolation, so only solitary tests are really unitary. Some others will argue that mocks are an heresy. I guess “it depends”: are we talking about mocking another method, another class or the whole AWS cloud?
- In serverless applications, and more precisely in Lambda functions, we generally have very few business logic, and most of the code is made of calls to other AWS services (retrieving a file in S3, pushing a message to SQS, …). Does it make sense in that case to write a lot of solitary tests and mock all these external calls?
I won’t participate into this religious war. I just wanted to introduce these two types of tests that I will use in the next sections.
Testing options
For the rest of the article, I will use the architecture represented in the following diagram:

Something quite standard with API Gateway, Lambda & Dynamo but not too simple: Dynamo Stream, SQS and some kind of connection to a legacy database and backend. Let’s say the application ingest some external data, process it, store it and also synchronise with a legacy backend.
Note that all the options are not mutually exclusive and I’ll give my strategy on these options in the conclusion.
Option #1: Solitary tests
As quickly introduced, solitary tests permit to validate a piece of code without its dependencies, completely isolated from the external world. In the case of serverless applications, it means you test the Lambda function code independently from the cloud. There are different ways to do so:
1. Using mock libraries
At the test level, you can leverage libraries such as Mockito (for Java), sinon.js (for javascript) or unittest.mock / moto (for python) to mock dependencies. We generally use them to mock the AWS SDK calls. You can have a look at this AWS blog post (“Mocking modular AWS SDK for JavaScript v3 in Unit Tests”) explaining how to use aws-sdk-client-mock to easily mock the AWS Javascript SDK v3:
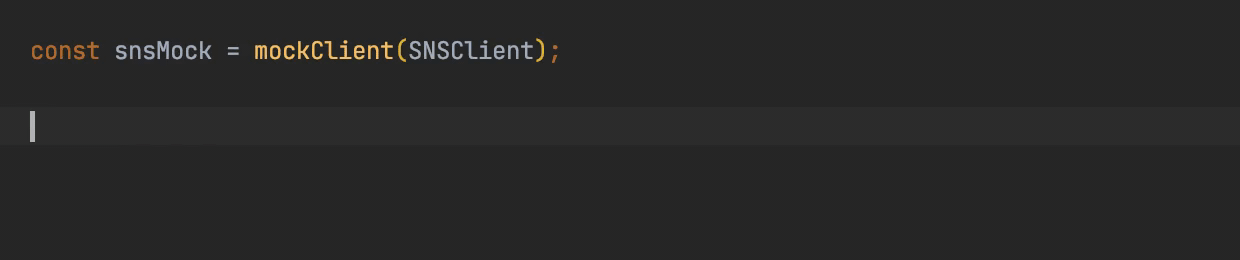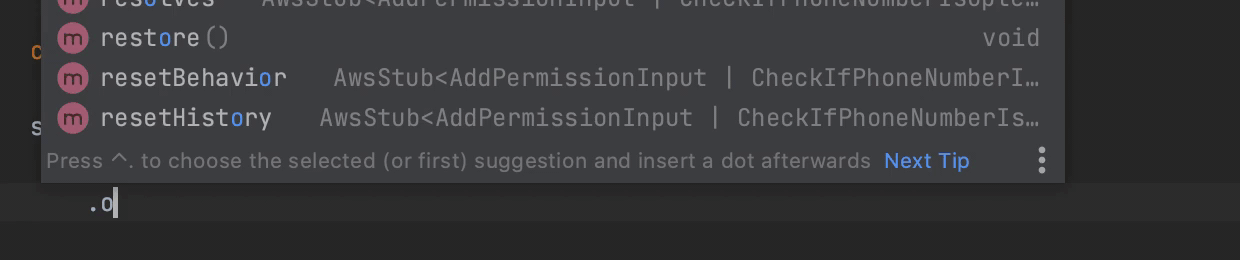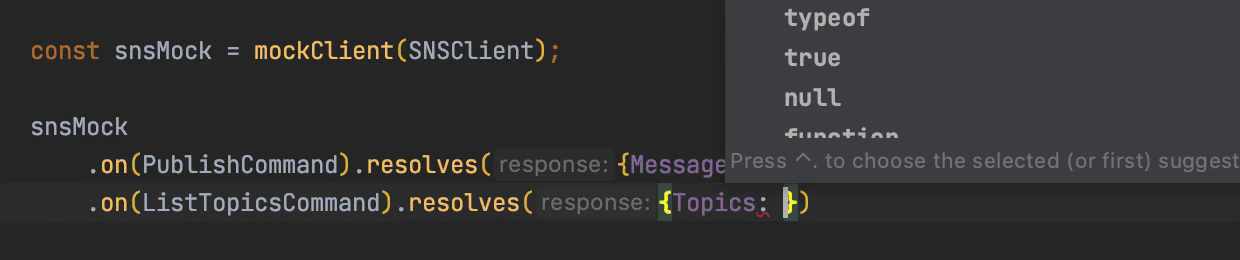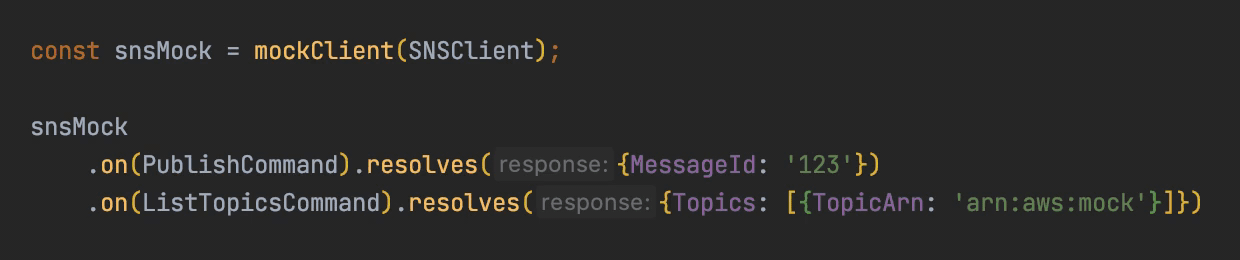
This approach is great if you have a limited number of dependencies to mock, let’s say one or two SDK calls. Otherwise, it becomes painful to mock everything: you have to write a lot of code to specify what the dependencies are supposed to do and return, you sometime have to guess what the response really are, and potentially make errors. This leads me to the second way.
2. Using hexagonal architecture
When your Lambda function is growing (be careful not to grow recklessly) or simply to avoid mocking AWS services, you should probably think about decoupling your code: decoupling the business logic from the external dependencies. Hexagonal architecture can help achieving this by using ports and adapters to isolate the core business (also called domain) from the outside world:
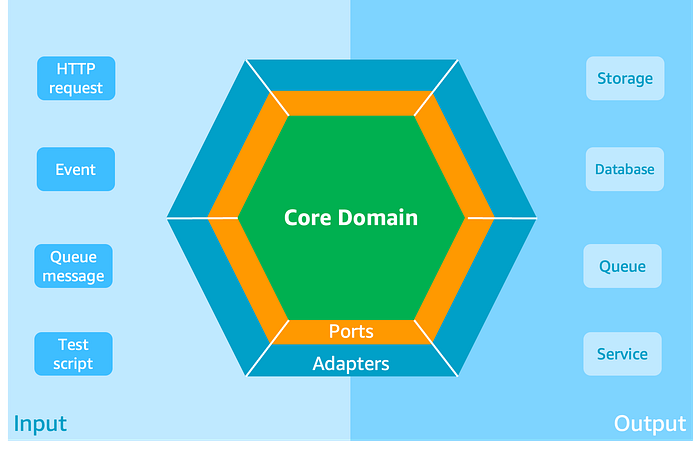
Ports provides the ability for external actors to interact with the domain (input) and the domain to interact with external actors (output). Put simply, they are interfaces. Adapters provides the logic to interact with these external actors, they are the implementation.
For a Lambda function, it would be pretty much the same: the handler function with the event would be an input adapter, while interactions with DynamoDB, SQS, etc. would be handled by output ports and adapters. If you are interested to dive deeper, have a look at this blog post (“Developing evolutionary architecture with AWS Lambda”).
One obvious advantage is that it simplifies unit testing (or solitary testing to be more precise) as we don’t have to mock AWS SDK calls anymore. We can simply provide stubs or mocks for the ports (fake adapters). It makes the code easier to produce and to read. It has other benefits, like maintainability and evolutivity but it also requires a bit of investment. We have nothing without nothing!
3. Using “local cloud” frameworks
Have you ever dreamed about having the cloud in your computer? This is the promise of Localstack: “A fully functional local cloud stack. Develop and test your cloud and serverless apps offline!”. Looks promising, isn’t it?! All you have to do is to install (pip install localstack ) and start (localstack start) LocalStack, and change the AWS SDK endpoint to the local address within your code. Here is an example with DynamoDB:
import AWS = require('aws-sdk');let docClient = new AWS.DynamoDB.DocumentClient( {
region: "eu-west-1",
endpoint: "http://localhost:4566"
});
The benefit is that you don’t have to write your mocks anymore: you are testing against a complete mocked cloud, on your computer! You also don’t need to deploy anything on the cloud and thus reduce your bill.
Except that the reality is not yet at the level of the promise. Multiple reasons to this:
- Localstack does not provide all the features AWS is providing (see the coverage). Some features are not supported and some are partially supported… Obviously, the two companies don’t have the same number of engineers working on their respective products.
- On partially supported features, there may be (actually, there are) discrepancies with the cloud. And having your tests green locally doesn’t mean it will work when deployed on AWS.
- Last but not least, it’s not that easy to setup and you soon find yourself troubleshooting LocalStack rather than your application, adding some glue code or even modifying your own application to be testable against LocalStack. I recommend you to have a look at this article (“Is it possible to do cloud development without the cloud?”) for more concrete feedback on the tool.
I’d really like to have a “fully functional local cloud”, but this is not currently the case and I would not recommend it for now.
4. Wrap-up
Let’s rate our solitary tests against the four criteria given in introduction (0 is the lowest, 5, the highest score):
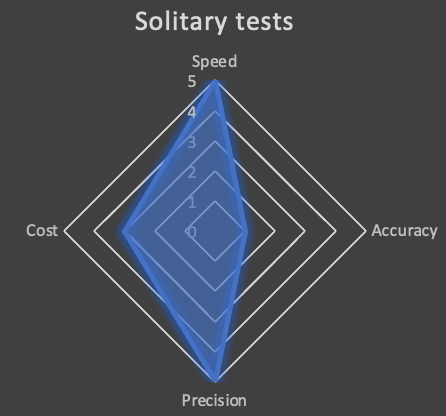
Solitary tests have the main advantage to be really quick and precise (both 5). On the other side, as we test our code in complete isolation and using mocks, we cannot guarantee that it will actually work as expected once deployed (1 on the accuracy). I’m giving 3 for the cost as it actually takes human time to setup tests, configure mocks, or build an hexagonal architecture, and we all (should) know that the hourly cost of an engineer is much higher than a couple of Lambda functions or SQS queues…
My 2 cents:
- Use solitary tests for your core domain (business logic) and avoid mocking.
- Favour a clean architecture, if not hexagonal (because it can be heavy to implement), at least have your business logic separated from all the cloud stuff (even the handler).
Looking at our example, we would use some solitary tests for the business layer in the first and last Lambda function, to validate the data processing (transformation, aggregation, …):

Option #2: Sociable tests with emulated Lambda
We are now moving to the sociable tests, where the tested code is not completely isolated from its dependencies. There are no mocks anymore in this situation. Applied to Lambda, it means the function will actually perform real calls to real AWS services, deployed on a real cloud.
I’m adding the fact that Lambda is “emulated”: it means we don’t invoke the real Lambda function deployed on AWS, but a local version, in order to speed up the tests. You can actually do this using AWS SAM (sam local invoke MyFunction) or the Serverless framework (serverless invoke local -f MyFunction). Behind the scene, it uses Docker and bootstrap an environment similar to the AWS Lambda Runtime you select (Java, Python, ...), deploy your code on it and invoke the function.
We can even go a bit further by testing API Gateway locally and its integration with Lambda and validate the invocation of the function with the proper event (using sam local start-api). The same can be done with Step Functions local. This permits to ensure our function understands and is able to parse the event it receives (at least coming from these 2 services).
For the other sources, you will have to look at the documentation for event examples. SAM can also generate some of them (about 30), including DynamoDB stream event and SQS message event, both useful in our specific example: sam local generate-event dynamodb update / sam local generate-event sqs receive-message).
If we want to automate these kind of tests, we’ll need to write scripts, use the SAM CLI / Serverless CLI for the execution and the AWS CLI for the assertions. It’s probably not what developers are the more comfortable with (compared to test frameworks like JUnit or Jest)...
Because we test agains real services, it means we need to deploy part of the infrastructure (DynamoDB / SQS / RDS), which can be a bit tricky so generally we deploy everything. In such case, we may have troubles to test services like SQS, which are not an ending state. Indeed, we have a Lambda function that consumes the messages on the queue and therefore cannot assert on the presence of the message in this queue. To overcome this, we can create a testing queue, with no consumer on it. It has some implications on your infrastructure code. Here’s a example of SAM template:
AWSTemplateFormatVersion: 2010-09-09
Description: >-
sam-sqsTransform:
- AWS::Serverless-2016-10-31Parameters:
# Use the command: sam deploy --parameter-overrides 'EnvType="test"'
# to deploy the test environment (and testing SQS queue)
# Use sam deploy only for production deployment (in a CI/CD pipeline)
EnvType:
Description: Environment type.
Default: prod
Type: String
AllowedValues:
- prod
- test
ConstraintDescription: must specify prod or test.Conditions:
Testing: !Equals
- !Ref EnvType
- testResources:
RealQueue:
Type: AWS::SQS::Queue TestingQueue:
Type: AWS::SQS::Queue
Condition: Testing # only created when the condition is met SQSPublisher:
Type: AWS::Serverless::Function
Properties:
Description: A Lambda function that send messages to a queue.
Runtime: nodejs16.x
Architectures:
- x86_64
Handler: src/handlers/sqs-publisher.handler
Policies:
- AWSLambdaBasicExecutionRole
- SQSSendMessagePolicy:
QueueName:
!If [Testing, !GetAtt TestingQueue.QueueName, !GetAtt RealQueue.QueueName]
Environment:
Variables:
# give the appropriate queue reference according to the condition (test or not)
SQS_QUEUE: !If [Testing, !Ref TestingQueue, !Ref RealQueue] SQSConsumer:
Type: AWS::Serverless::Function
Properties:
Description: A Lambda function that logs the payload of messages sent to an associated SQS queue.
Runtime: nodejs16.x
Architectures:
- x86_64
Handler: src/handlers/sqs-payload-logger.handleroked
Events:
SQSQueueEvent:
Type: SQS
Properties:
# This function remains plugged to the real queue
Queue: !GetAtt RealQueue.Arn
MemorySize: 128
Timeout: 25
Policies:
- AWSLambdaBasicExecutionRole
Looking at our example, we get the following diagram:
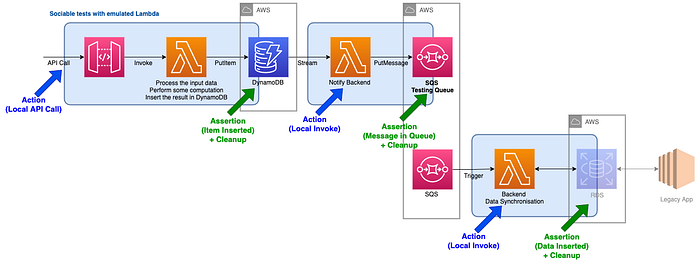
In terms of pricing, you can have 1 million messages on SQS, 1 million Lambda executions and 2.5 millions DynamoDB stream reads per month for free. If DynamoDB and SQS are quite cheap in a test environment, we must choose carefully our RDS or Opensearch instance type. AWS generally provides free tier (e.g. 750 hours for an RDS db.t2.micro + 20 GB of storage or 750 hours for an OpenSearch t3.small.search + 10 GB of storage) but definitely something to be aware of.
If we try to rate this kind of tests against the four criteria:
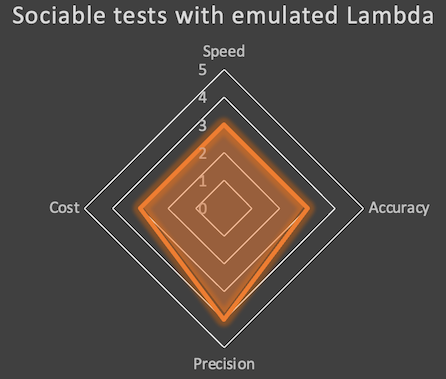
- These tests are slower (3): infrastructure must be deployed (at least once) and local invocation is much slower (starting Docker, “deploying” the function) than just running unit tests.
- The accuracy is a bit better (3) for the interaction of our Lambda functions, but we are still on emulated environment, with no verifications of the permissions.
- Precision is also pretty good (4), even if not at the level of unit tests as we don’t solely test a specific piece of code but the whole function.
- As for the cost, I keep a 3 because we can test most of our architecture thanks to the free tier. But automating the tests is also more complex and will take more time.
My 2 cents:
- Don’t base your testing strategy on these tests, don’t try to have a strong coverage based on these. They are not easy to automate and a bit slow (using CLI tools).
- You can eventually use the SAM or Serverless CLI to execute and debug (breakpoint / step-by-step) your function locally.
Option #2bis: Sociable tests
We cannot leverage the CLI tools mentioned in option #2 at scale and build a complete test harness with them (too slow and hard to automate). So instead of using them, why not simply invoking the handler method of our Lambda function, but keeping the call to real services. The picture is very similar to the previous one apart from the actions performed:
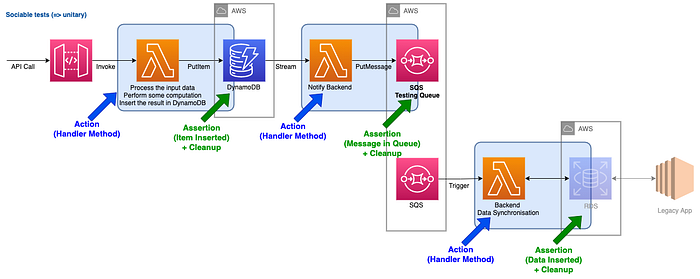
There are two advantages doing this:
- First and that’s really important in terms of developer experience: we can leverage standard testing libraries. It’s much easier to write tests in our preferred language and with our usual tools. We can obviously use the SAM CLI to generate the events and import them in our test resources.
Self-promo: In Java, you can use a library I wrote (aws-lambda-java-tests) to simplify test writing, by injecting the events in your tests:
@ParameterizedTest
@Event(value = "sqs/sqs_event.json", type = SQSEvent.class)
public void testInjectSQSEvent(SQSEvent event) {
// test your handleRequest method with this event as parameter
}Or even more powerful:
@ParameterizedTest
@HandlerParams(
events = @Events(folder = "apigw/events/", type = APIGatewayProxyRequestEvent.class),
responses = @Responses(folder = "apigw/responses/", type = APIGatewayProxyResponseEvent.class))
public void testMultipleEventsResponsesInFolder(APIGatewayProxyRequestEvent event, APIGatewayProxyResponseEvent response) {
// will inject multiple events (API GW requests) and assert responses of the Lambda
}- The other advantage is the speed of the tests: there’s no emulated Lambda environment to bootstrap, no Docker. You still have to deploy the rest of the infrastructure, as we want to test against the cloud, but once deployed and if you just modify the functions’s code, it remains quite fast.
Rating this option is quite similar to the previous one except the two advantages I’ve just explained:
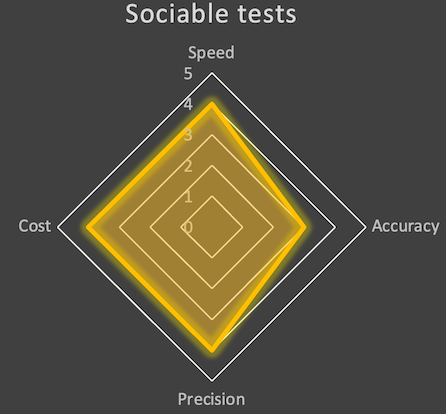
- Increased speed, which leads to a 4.
- Reduced complexity of implementation and thus costs, moving to 4 too.
- Accuracy and precision remain the same.
My 2 cents:
- Favour this kind of tests as they provide a very good balance on each criteria.
- Do not solely rely on these tests, we are still missing some part (permissions, real events/triggers), see options #3 or #4.
Going further
If you don’t want to bother with a testing SQS queue and reduce the risk on the infrastructure part, I would suggest to extend the test like in the following picture. It tends to become an integration test and you will loose some precision in the feedback, but you keep your infra as code straight to the point.
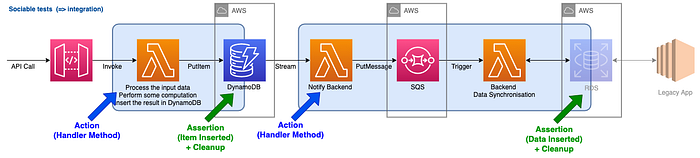
On the other side, when testing some other serverless components, you may need to add further infrastructure to be able to perform the assertions. For example with SNS and EventBridge, it is not possible to poll the topic or the bus, so we need a way to assert that a message/event was correctly received. To do so, we can add a testing SQS queue:
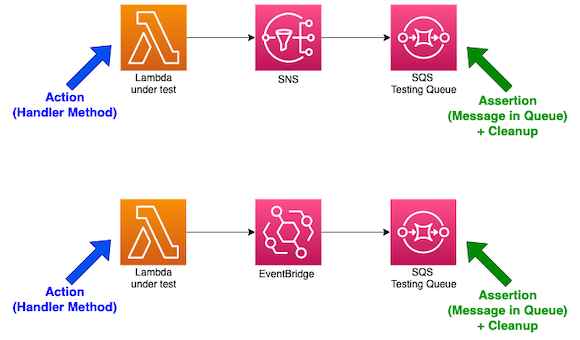
My 2 cents:
- Set the
MessageRetentionPeriodto the minimum (60 seconds) on your testing queue so that messages older than one minute will be automatically purged (just in case your test didn’t clean up correctly). - I would encourage to have one AWS account per developer. Doing so, you reduce the risk of going beyond the free tier on one single account and you reduce the risk of collision during tests (everyone using the same SQS queue…). If not possible, be sure to deploy one stack per developer and define a naming convention (e.g. “nickname-mystack“).
Option #3: Integration tests
In all the previous options, we are missing two essential aspects:
- The trigger of the function (integration with an upstream service): API call, DynamoDB stream, SQS polling.
- The Lambda function permissions (execution role) to interact with downstream services.
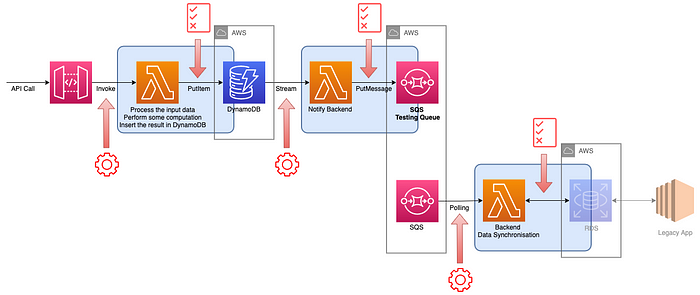
Integration tests permit to cover this: we don’t invoke the Lambda function ourself locally but use the upstream service to trigger the deployed Lambda function which will then interact with the real services. Looking at our sample, it looks like this:
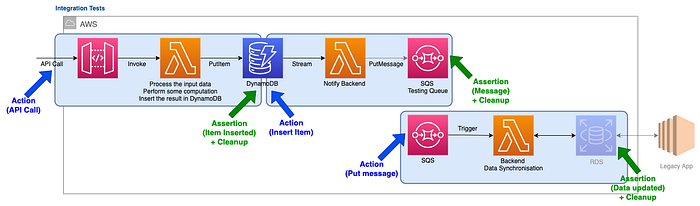
We can still use our preferred programming language and tools to write these tests, which makes authoring them quite convenient. We leverage the AWS SDK to perform the actions and the assertions or in the case of an API simply request the endpoint.
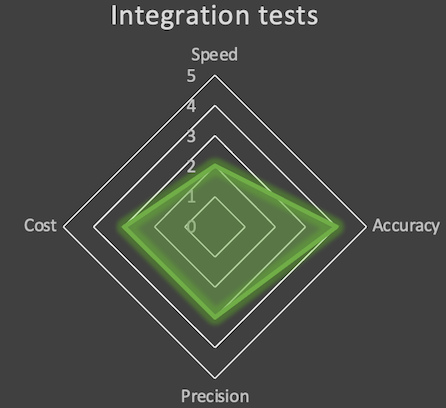
Rating this option, we are gaining in accuracy (4) what we are losing in precision (3): we test the real services, integrated altogether and deployed on AWS which gives a very good accuracy, but when a test is failing, it becomes harder to identify the exact cause (is this even because of our Lambda function?). We also have slower tests (2): invoking a rest api, inserting items in a DynamoDB table, … takes undoubtedly more time and adding the trouble shooting time too. Talking about costs, it’s slightly more complex to implement and more time consuming to troubleshoot, which leads to a 3.
My 2 cents:
- Nothing really special, I don’t really recommend these tests. They provide a better accuracy, but still not optimal (see option #4).
Option #4: End-to-end tests
We’re arriving to our last option with the end-to-end tests. As their name suggests, the aim is to validate that the whole system is well integrated and works from end to end on the cloud. As for the integration tests, we will write our tests using JUnit/Jest/… and the AWS SDK. This time however, we are not splitting the job and we test the whole “feature”.
In our example, we validate that when calling the API with some data we have the expected output in the RDS database at the end:
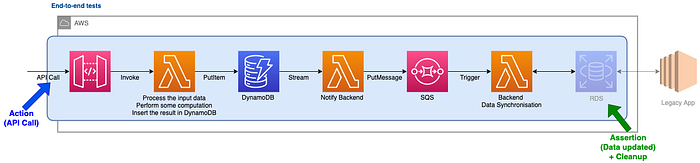
The main benefit of these tests is their accuracy: You deploy everything in the same way as it will be in production, with no testing queue or dedicated infrastructure. If the tests pass in your test environment, it should work the same later in production. Note that this is true only if you use infrastructure as code and framework like SAM, CDK or serverless and deploy the same infrastructure in the different environments. But who the hell deploys this by hand today?
On the other side, the big issue with these tests is the lack of precision when tests are failing. You have to troubleshoot each component of the chain to find out where is the problem. Hopefully AWS X-Ray and CloudWatch ServiceLens can help, but it’s not magical and not all services integrate with X-Ray. There are other tools you can leverage: CloudWatch Logs Insights to query your logs and search for errors or particular events, or CloudWatch Lambda Insights that gives you metrics for your serverless application.
Another downside of this kind of test is they are generally hard to setup. Not because of the infrastructure (with IaC), but because of the data. We need to get a clean dataset (in RDS in our example), potentially retrieve it from a production environment, which means anonymising the data, removing PII… Cleaning the data after the test may also be complex. It’s especially true on this type of tests as they are often executed on a shared environment (integration, UAT, preprod, you name it). Again it’s better if you can get a clean (unshared) environment where you can perform these tests, so that you can populate your DB with a fresh clean dataset each time. Infrastructure as code is here for that, use it!
Looking at the radar, we have the following chart:
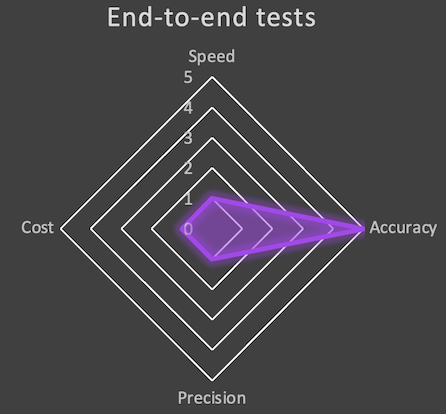
- As mentioned, accuracy is optimal (5), we test in real conditions (provided you have the right datasets).
- Precision is really low (1) and makes it much harder to troubleshoot.
- We are loosing in speed (1) as we need to deploy everything, the tests are also quite long to execute, and harder to troubleshoot also means we spend much more time on it.
- Time is money! That’s the main reason why I’m downgrading the rate to 1.
My 2 cents:
- Obviously, and the test pyramid and the honeycomb agree on this, do not invest too much in these tests. Use them to validate the different “paths” of your infrastructure. In our example, we have mainly one path, meaning one test. If we had for example an EventBridge somewhere with different rules that send the events to different targets, we would add a test for each rule. If we had a dead letter queue, we also would like to check the “error path”. More complicated with Step Functions: do we have to validate all the paths and conditions? You have to validate all the branches of your state machine, to make sure it is well configured and integrated with all the services it is calling.
- The objective here is to validate only what could not be validated before: integration between each service and permissions. If you can validate something with another kind of test, please do so.
- Do not run these tests continuously. Contrary to solitary and sociable tests that you want to run hundreds times a day, these tests are run less often, and generally not from your laptop but rather from your CI/CD pipeline. Remember they are slow, don’t wait for them.
Conclusion
We don’t really care about the shape of our tests, be it a triangle, an honeycomb or anything else. Here’s a flower:
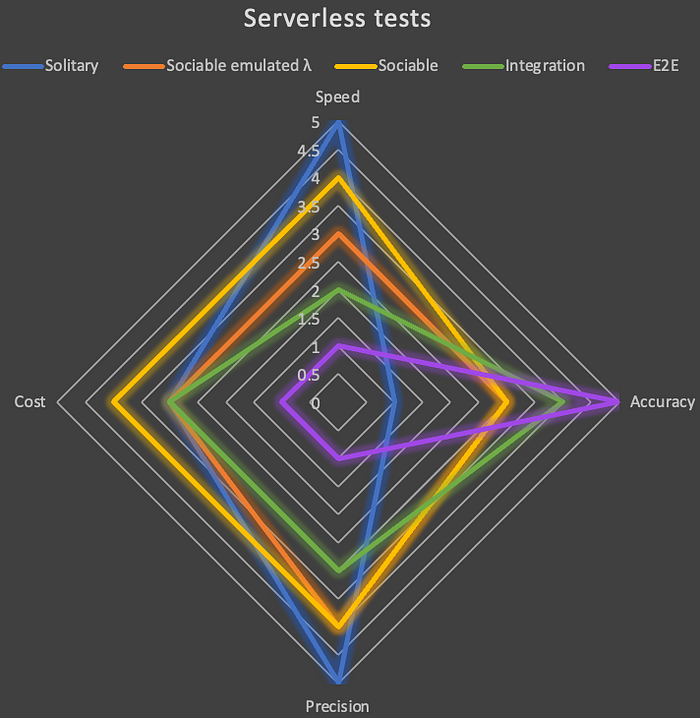
What we must care though, is to use the appropriate tests for the job. If I summarise:
- Use solitary tests for the business logic of your Lambda functions. Try as much as possible to extract this business from the handler, to avoid mocking, especially AWS mocking. Hexagonal architecture is a plus but not mandatory. That way you can test your business (if any) without deploying to the cloud. If the only “business” you have is to coordinate other AWS services, then maybe Step Functions would be a better fit, but that’s another topic.
- Don’t rely on sociable tests with emulated Lambda.
- Favour sociable tests: invoke your handler method locally without mocking external calls to the AWS services. These tests obtain the best score with 3.75/5 based on the four criteria listed in the introduction.
- Don’t rely on integration tests, prefer the end-to-end tests which provide a better accuracy, but don’t over invest on them. Just validate the infrastructure paths (integration between services: events & messages, configuration, permissions).
BONUS: this blog post focuses on automated testing, but as I mentioned developer experience, I must also speak about manual tests, and how to quickly test locally against the cloud. My recommendation here is to leverage frameworks like sam accelerate or serverless stack (sts), which permits to update the lambda function code or a step function state machine without redeploying everything. It’s really fast and quite convenient.
Thank you if you read until there, hope you liked it and it resonates.
