Anonymize your data using Amazon S3 Object Lambda
Personal Data in Europe, Personal Identifiable Information (PII) in the US, Client Identifying Data (CID) here in Switzerland, … Whatever the name you give it, the definition is slightly the same: it defines a category of information about an individual that can be used to unambiguously distinguish or trace his/her identity.
For example, passport numbers, social security numbers, IBAN or biometric records, known as direct identifying data, clearly identify an individual. Full names, addresses, phone numbers, dates of birth or emails can also be used to identify someone. However, as they can be shared by several people, you need to combine them to explicitly identify an individual — we say they are indirect identifying data.
This data, when maintained by a company, especially highly regulated one (Financial Services, Healthcare, …) or governing agency must comply with security standard and compliance certifications (GDPR, HIPAA, FINMA circulars, …). These certifications require this kind of data to be highly protected, from public leakage of course, but also internally from your own employees.
In this article, I will mainly focus on this second point. Today more than ever, data is key is to take appropriate decisions, create new services or improve existing ones. And if you want to share data internally, in order to build clever solutions, leveraging analytics and machine learning for example, you need to keep control on that data and ensure it remains compliant with aforementioned certifications.
Anonymization or pseudonymization are some of the technics commonly adopted to do protect some data. In both case, you want to remove the ability to identify someone and more important the link to his personal information (financial, health, preferences…), while keeping the data practically useful. Anonymization consists in removing any direct (and part of indirect) identifying data. Pseudonymization does not remove these information but modify them so that we cannot make a link with the original individual.
Multiple papers, algorithms (k-anonymity) and technics exist to perform anonymization and pseudonymization. AWS also provides 2 functions — available in the Serverless Application Repository — that use Amazon Comprehend and its ability to detect PII:

On my side, as the input file is pretty straightforward, I don’t need Comprehend to detect sensible information.

Here is my (naive) approach:
- Remove any (identifying) field that is not useful to the downstream process. In my example, the SSN (social security number) is clearly useless for a data analytics application or to perform machine learning. Same thing for the phone number, address and name.
- Remove some precision, by extracting only the meaningful part. For example, we don’t need the exact date of birth, an age may be enough.
- If for any reason, we need to keep some identifying fields, then we must pseudonymize them. For example, we can replace the name with another, randomly generated.
After this process, we should end up with the following information, clear from any identifying information (names have been replaced):

Now that we know what we want to do, let’s see it in the context of our workload.
We have 3 main components in our workload:
- A confidential application, that deal with these data, used by doctors and other medical staff. In that case, the data is not anonymized.
- A storage area (Amazon S3), where the data is kept as CSV files for further analytics. Raw data (with identifying information) is kept and protected with appropriate policies.
- Another application, used to perform some analytics on this data (without identifying information). Actually, there could be many more applications like this with each their specific requirements and compliance rules.
To provide anonymized data to these applications, we have several options:
- Create and maintain as many copies as there are applications with different requirements so that each one has its own version of the data.
- Build and manage a proxy layer with additional infrastructure, so that you can manage this anonymization process between S3 and the target application.
Both options add complexity and costs. So this is were I introduce S3 Object Lambda, a capability recently announced by AWS and that will actually act as this proxy. Except that you don’t have to manage any infrastructure, just your Lambda function(s).
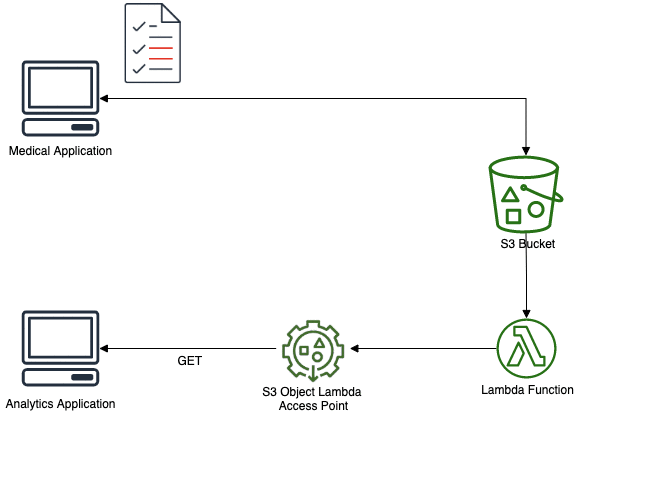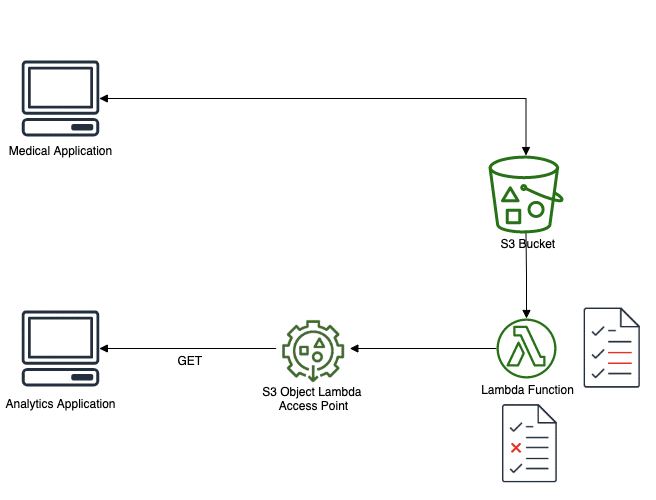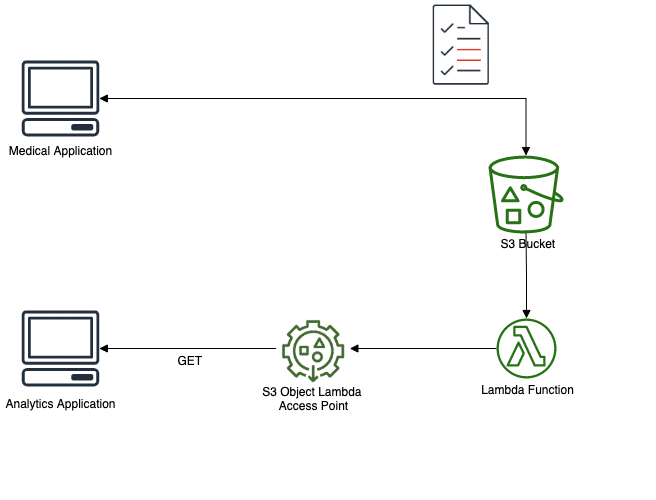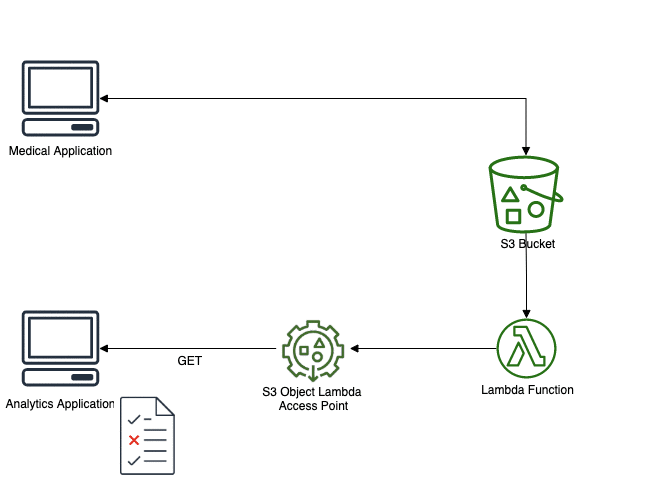
Let’s implement this solution. First thing to do is to create a Lambda function. To do so, use your preferred framework (SAM, Serverless, CDK, …). I use SAM and my function is in Python 3.8.
The function must have permission to WriteGetObjectResponse, in order to provide the response to downstream application(s). Note this is not in the s3 namespace but s3-object-lambda:
{
"Action": "s3-object-lambda:WriteGetObjectResponse",
"Resource": "*",
"Effect": "Allow",
"Sid": "WriteS3GetObjectResponse"
}And here is the code of my function (commented to understand the details):
My Lambda function is really simple and if you would like to get something more production-ready, I encourage you to have a look at the AWS samples, mentioned above.
Once the function is created and deployed, we need to create an Access Point. Amazon S3 Access Points simplify managing data access for applications using shared data sets on S3, exactly what we want to do here. Using the AWS CLI:
aws s3control create-access-point --account-id 012345678912 --name anonymized-access --bucket my-bucket-with-cidThen we create the Object Lambda Access Point. It will make the Lambda function act as a proxy to your access point. To do so with the AWS CLI, we need a JSON file. Be sure to replace with your account id, region, access point name (previously created) and function ARN:
Finally, we create the Object Lambda Access Point using the following command:
aws s3control create-access-point-for-object-lambda --account-id 012345678912 --name anonymize-lambda-accesspoint --configuration file://anonymize-lambda-accesspoint.jsonAnd that’s it! You can now test your access point and the anonymization process with a simple get. Note that you don’t perform a get directly on the S3 bucket, but on the access point previously created, using its ARN, just like that:
aws s3api get-object --bucket arn:aws:s3-object-lambda:eu-central-1:012345678912:accesspoint/anonymize-lambda-accesspoint --key patients.csv ./anonymized.csvYou can now provide this access point ARN to the analytics application so it can retrieve anonymized data and perform whatever it needs to.
In this article, I’ve shared how to leverage S3 Object Lambda in order to anonymize your data. In just a few commands and a bit of code, we can safely share data containing identifying information with other applications without duplicating it or building a complex infrastructure.
Note that you can use the same technology to enrich some data (retrieving information in a database), or modify it on the fly (eg. image resizing), or modifying the format (eg. xml to json, csv to parquet, …), and I guess you will find some usage too.
The code of this article is available in github, together with a full sam template to create everything (bucket, access points and Lambda function).
